


We searched the internet for a variety of information about cloud providers, and it turns out that all of them are supported by the same architecture. It is known as “Serverless”.
According to the definition, serverless computing is an approach to cloud computing execution in which the cloud provider manages the servers on behalf of their clients by allocating machine resources as necessary. However, the capacity planning, setup, management, maintenance, fault tolerance, or scaling of containers, virtual machines, or physical servers is not a problem for developers of serverless apps. The outcomes of serverless computing are stored after being processed in brief bursts rather than in volatile memory. Serverless vendors offer to compute runtimes, also known as Function as a Service (FaaS) platforms, which don't keep files but instead carry out application logic. Serverless functions are the common name for applications that are deployed employing a serverless computing technique. Public cloud service providers offer services for running serverless functions, such as AWS Lambda and Azure Functions.
“Google Cloud Functions” is an innovative tool that was recently introduced by the Google Cloud Platform, the company's public cloud infrastructure that developers may use to build and manage their apps. The tool, which enables programmers to create actions that are triggered in response to certain events, is noteworthy because it is very similar to the well-liked Lambda service from industry leader Amazon Web Services, which provides public cloud services.
Google Cloud's solution for serverless container deployment and execution is “Cloud Run”, which is powered by Knative. By using a Docker (OCI) container image and executing it as a stateless, autoscaling HTTP service, it enables developers to run pre-built apps.
Cloud Run is concentrated on container-based development, as opposed to the source-based AWS Lambda and Azure Functions, enabling you to run applications serving many endpoints on a higher scale and with fewer architectural constraints. A completely managed platform, Cloud Run.

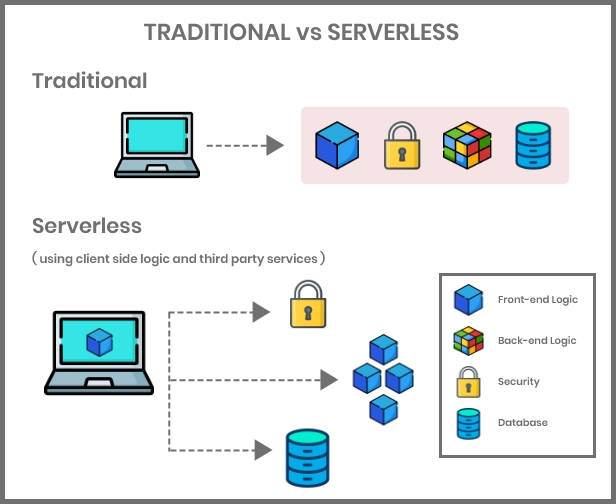
Why Serverless? 🧊
Although "serverless" computing does in fact use servers, the servers are never a concern for developers. The vendor is in charge of them. This can lower the amount of money spent on DevOps, allowing developers to construct and enhance their apps without being limited by server capacity.
That means:-
There is no necessity for server administration.
Developers are only charged for the server space that they utilize, which saves money.
Scalability is built-in to serverless architectures.
It is feasible to deploy and upgrade software quickly.
Code can execute closer to the end user, minimizing latency.
Security risks 🛡️
Serverless functions accept input data from a range of event sources, including HTTP APIs, cloud storage, IoT device connections, and queues, until the security chapter enters the equation. Because some of these portions may contain untrusted communication formats that are not properly examined by normal application layer security, the attack surface is dramatically increased. If the communication links employed to get input data (such as protocols, vectors, and functions) are vulnerable, they might be exploited as attack vectors.
Serverless apps are vulnerable to cyber assaults owing to insecure setups in the cloud service provider's settings and functionalities. Denial-of-Service (DoS) attacks, for example, are common in serverless applications owing to incorrect timeout settings between functions and the host, where the low concurrent limitations are leveraged as sites of attack against the program.
The usage of microservices in the design of serverless applications exposes the movable elements of the separate processes to authentication failure. In an application with thousands of serverless functions, for instance, if just one function's authentication is handled poorly, the remainder of the program suffers.
The Obvious Question: “What are the best practices while employing serverless services?”
The most common problem of all is a cold start. The infrastructure must create a new container and pack your code into it. It can take many seconds to instantiate a service that is expected to reply in single-digit milliseconds. That's a bad way to get started, and you'll want to avoid it. The lag time might be significantly greater if you have a chained architecture with various serverless services that have all gone cold.
Throttling is a second issue that might harm serverless. Many services limit the number of serverless instances that they can employ to cut expenses. During periods of high activity, the number of instances may exceed its maximum, and replies to subsequent incoming requests may be delayed or even fail. Throttling can be solved by fine-tuning the restrictions to cover genuine peak consumption while preventing excessive usage caused by a denial-of-service attack or a flaw in another section of the system.
A third issue with the serverless design is that the storage layer may be unable to manage peak demand and may back up the running serverless processes despite the availability of several instances. One option is to employ memory-resident caches or queues, which can absorb data from a peak and then trickle it out to the database as fast as the database can commit the data to disk. A lack of monitoring and debugging tools can contribute to all of these problems, making them extremely difficult to identify. You'll notice that "vendor lock-in" isn't listed as a risk. As you'll see, this is more of a compromise than a genuine issue.
Here are some suggestions that might help in avoiding the above-mentioned issues:
Increase memory allocation
Choose a faster runtime for workloads that are sensitive to startup time.
Keep shared data in memory by loading outside the main event handler function.
Shrink package size.
Keep a pool of pre-warmed functions or set up regular jobs (CRON).
Serverless technologies, which offer a wide variety of features like automatic scaling, built-in high availability, and a pay-for-use billing model to increase agility and optimise costs, are something that every organisation should adopt.
This sums up our short introduction to Serverless Computing, stay tuned for more such exclusively exciting content!